






















Originally published December 15, 2018 @ 9:14 pm
The ‘t’ is an excellent Ruby-based CLI utility for interacting with the Twitter API written by Erik Berlin. This is certainly not the only such tool available, but, in my estimation, it is the most full-featured and expertly-written. No amateur-hour coding here.
Here I am showing how to install and use t on CentOS 6. I am a professional Unix sysadmin and so getting me to upgrade anything takes a lot of incentive. Having said that, installing t on a more recent version of Linux is, obviously, a lot easier.
Installing Things
First, we’ll need to install some prerequisites. Mostly Ruby-related stuff for obvious reasons:
yum install ruby ruby-devel yum install gcc g++ make automake autoconf curl-devel openssl-devel zlib-devel httpd-devel apr-devel apr-util-devel sqlite-devel yum install ruby-rdoc ruby-devel yum install rubygems
At this point I realized that I need Ruby 2.2+ and that’s not on tap for my OS version. So I had to get it the hard way:
yum install gcc-c++ patch readline readline-devel zlib zlib-devel yum install libyaml-devel libffi-devel openssl-devel make yum install bzip2 autoconf automake libtool bison iconv-devel sqlite-devel curl -sSL https://rvm.io/mpapis.asc | gpg --import - curl -L get.rvm.io | bash -s stable source /etc/profile.d/rvm.sh rvm reload rvm requirements run rvm install 2.2.4 rvm use 2.2.4 --default ruby --version
And now to install t itself:
gem install t
Twitter Authorization
twurl (https://github.com/twitter/twurl) to handle authorization.
twurl authorize --consumer-key ***** --consumer-secret ***** # You will need to open the displayed URL, approve the app access, and copy back the displayed PIN. /bin/cp -p ~/.twurlrc ~/.trc t accounts
For a complete overview of the available t commands, just hop over to it’s developer’s GitHub page.
Installing Optional Tools
When dealing with Twitter API, you’re likely to run into lots of CSV files. Dealing with CSV can be a pain, especially when the data is complex and multi-lingual. The csvfix tool will help you to fix your CSV files and massage them in various ways.
wget https://bitbucket.org/neilb/csvfix/get/version-1.6.zip unzip version-1.6.zip cd neilb-csvfix-e804a794d175 make lin cd csvfix/bin /bin/cp csvfix /usr/bin
The `timeline-csv-analysis.sh` script I forked from some dude’s coursework repo and modified it somewhat. What this script does now is it grabs the last whatever number of your tweets ad a list of common English words. And then it shows you most common hashtags (minus the most common words), likes, retweets, etc.
wget -O ~/timeline-csv-analysis.sh --no-check-certificate https://raw.githubusercontent.com/igoros777/compciv/master/homework/congress-twitter/timeline-csv-analysis.sh chmod 750 ~/timeline-csv-analysis.sh cd ~ mkdir ~/data-hold/ ~/timeline-csv-analysis.sh igor_os777 1000 #last number shows how many tweets to download
And just in case you’re wondering, here’s what the output of this script looks like for me:
Some Examples
The function below will search the latest tweets for keywords picked at random from your keyword list. And then it will follow a few authors of those tweets. Some of the variables here:
max_keywords – the number of words to pick at random from the keyword array
max_count – the maximum number of people to follow
logfile – the log file used to store script output and make sure you don’t try to follow people you already following
function func_follow_keyword() {
echo "Following by keyword"
declare -a follow_keywords=('linux' 'gnulinux' 'sysadmin' 'opensource' 'ubuntu' 'kalilinux' 'gnu' 'kernel' 'devicetree' 'network_security' 'computer_security' 'blockchain' 'bitcoin' 'machine_learning' 'artificial_intelligence' 'Android' 'AppDev' 'BigData' 'CloudComputing' 'Datamining' 'Hadoop' 'Microsoft' 'OpenFlow' 'OpenCloud' 'OpenSource' 'PredictiveAnalytics' 'Techfail' 'VMWare' 'WebDev' 'WebDesign' 'ZeroDay')
for i in $(printf '%s\n' ${follow_keywords[@]} | shuf | head -${max_keywords})
do
k="$(echo ${i} | sed -e 's/^/#/g' -e 's/_/ #/g')"
q="lang:en ${k}"
echo "Following based on keyword: ${q}"
t follow $(t search all "${q}" -n ${max_count} | grep -vP "\bRT\b" | grep -v "${u}" | grep -v -P "@.*http" | \
grep -P -B1 http | grep -P '^[ ]{1,}@\S*' | grep -vP "$(grep "t unfollow " "${logfile}" | \
grep -oP '@\S*' | sed -s 's/[`]//g' | sort -u | xargs | sed 's/ /|/g')" | xargs)
echo ""
done
}
Here’s another function that will retweet a certain number of tweets based on keyword. The variables here are some of the same from the previous example. The one extra touch here is the favorite_exclude variable that is set by scanning the logfile for users you have unfollowed in the past.
function func_retweet_by_keyword() {
echo "Retweeting by keyword"
declare -a favorite_keywords=('linux' 'gnulinux' 'sysadmin' 'opensource' 'ubuntu' 'kalilinux' 'gnu' 'kernel' 'devicetree' 'network_security' 'computer_security' 'blockchain' 'bitcoin' 'machine_learning' 'artificial_intelligence' 'Android' 'AppDev' 'BigData' 'CloudComputing' 'Datamining' 'Hadoop' 'Microsoft' 'OpenFlow' 'OpenCloud' 'OpenSource' 'PredictiveAnalytics' 'Techfail' 'VMWare' 'WebDev' 'WebDesign' 'ZeroDay')
favorite_exclude="$(grep "delete favorite" "${logfile}" | grep -oP "\b[0-9]{19,}\b" | sort -u | xargs | sed 's/ /|/g')"
for i in $(printf '%s\n' ${favorite_keywords[@]} | shuf | head -3)
do
k="$(echo ${i} | sed -e 's/^/#/g' -e 's/_/ #/g')"
q="lang:en ${k}"
echo "Retweeting based on keyword: ${q}"
t retweet $(t search all "${q}" -n ${max_count} --csv | grep -P "^[0-9]{19}," | grep -vP "(RT)\s" | awk -F, '!($3 in a){a[$3];print}' | awk -F, '!($4 in a){a[$4];print}' | grep -P "http(s)?:" | awk -F, '{print $1}' | grep -oP "^[0-9]{19}" | grep -vP "${favorite_exclude}" | shuf | head -n ${max_count_retweet} | xargs)
echo ""
done
}
The function below will delete your tweets that contain specified keywords. This can be useful if you’re using a bot to post some of your tweets and sometime undesired material sneaks in.
function func_delete_keyword() {
echo "Deleting by keyword"
declare -a delete_keywords=('best_deals' 'black_friday' 'kinjadeals' 'amazondeals')
for i in $(printf '%s\n' ${delete_keywords[@]})
do
k="$(echo ${i} | sed 's/_/ /g')"
echo "Deleting based on keyword: ${k}"
for id in $(t search timeline @${u} "${k}" --csv | grep -v ^ID | grep ",${u}," | awk -F, '{print $1}')
do
echo y | t delete status ${id}
done
echo ""
done
}
Similar to the previous example, the function below will delete your tweets that tell you can buy something for a price. Very simple but surprisingly effective.
function func_delete_ads() {
echo "Deleting ads"
echo y | t delete status $(awk -F, '{print $1}' <(t search timeline --csv | grep -v ^ID | \
grep ",${u}," | grep -P '$[0-9]{1,}(,)?(\.[0-9]{1,})?\s' | grep -v illion) | xargs)
}
Here’s another function – and, I promise, the last one – it will unfollow people who haven’t tweeted in a long time. The threshold is specified in months.
function func_unfollow_stale() {
echo "Unfollowing stale"
(( threshold = threshold_months * 30 * 24 * 60 * 60 ))
t followings -l --sort=tweeted --csv | grep -v "^ID," | while read i
do
last_tweeted="$(date -d"$(echo "${i}" | awk -F, '{print $3}')" +'%s' 2>/dev/null)"
if [[ ${last_tweeted} =~ ${re} ]] ; then
screen_name="$(echo "${i}" | awk -F, '{print $9}')"
(( time_diff = this_time_epoch - last_tweeted ))
if [[ ${time_diff} =~ ${re} ]] ; then
if [ "${time_diff}" -ge "${threshold}" ]
then
echo "@${screen_name}" >> "${tmpfile}"
fi
fi
fi
done
t unfollow $(cat "${tmpfile}" | xargs)
/bin/rm -f "${tmpfile}"
}
So there you go: Twitter is pretty much a bunch of cron jobs conversing with each other.
Added bonus: deleting your old tweets
The first step is to download your tweet archive. Tweeter’s own documentation for this process is outdated. You do need to go into “Account Settings”, but then you go to “Your Twitter Data”, scroll all the way to the bottom, and under “Download your Twitter data” select “Twitter”.
You will see something like the screenshot below and the process will take a long while, so go grab a coffee or, better yet, go to sleep.
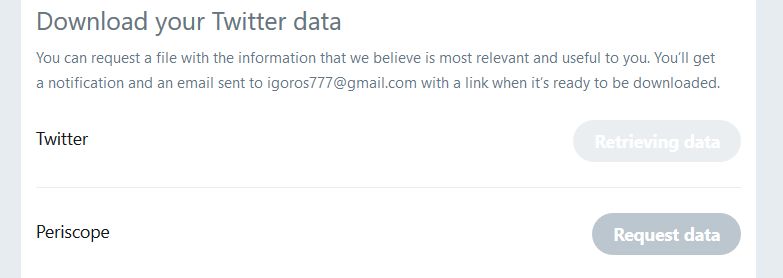
Early in the morning check your email for the download link from Twitter. A word to the wise: check your spam folder, for this is where Twitter emails usually end up (or should end up). Depending on the severity of your social media disorder, the archive file may be large: mine was 2GB+ compressed.
The file you eventually download will be twitter-YYYY-mm-dd-*.zip. The only file you need from this archive is tweet.js, so you can save yourself some time by just unzipping what you need:
unzip -p twitter*.zip data/tweet.js > tweet.js
After extracting the file, remove this string from it: window.YTD.tweet.part0 = . Make sure the first line of the file now begins with a left square bracket [
There are many elements associated with each tweet in this file, but our aim here is simple: find your tweets older than, say, six months, and delete them, if they don’t have any likes or re-tweets. The script below is not the most efficient, but it will get the job done eventually. You can also download it here.
#!/bin/bash
# Parse Twitter's 'tweet.js' data file and delete old posts that have no likes or retweets
# For details see https://www.igoroseledko.com/installing-t-cli-power-tool-for-twitter/
# Extract tweet.js from Twitter data archive and remove this string from it:
# window.YTD.tweet.part0 =
# Make sure the first line of the file now begins with a left square bracket [
if [ -z "" ]; then
echo "Specify the location of tweet.js"
exit 1
else
infile=""
fi
if [ -z "" ]; then
echo "Specify the username without '@'"
exit 1
else
u=""
fi
if [ ! -f "${infile}" ]; then
echo "Input file ${infile} not found. Exiting..."
exit 1
fi
T="/usr/local/bin/t"
if [ ! -x "${T}" ]; then
echo "Unable to access ${T}"
exit 1
fi
read -r ux <<<$(${T} accounts | sed 'N;s/\n/ /' | grep "${u}" | awk '{print $2}')
${T} set active ${u} ${ux}
f="$(mktemp)"
mt="$(date -d '3 months ago' +'%s')"
echo "Writing Tweet IDs to ${f}"
id_check() {
if [ ! -z "${id}" ] && [ ! -z "${fc}" ] && [ ! -z "${rc}" ] && [ ! -z "${ct}" ]
then
if [ ${fc} -eq 0 ] && [ ${rc} -eq 0 ] && [ ${ct} -lt ${mt} ]
then
echo "${id}" | tee -a "${f}"
fi
fi
}
line_parse() {
read id <<<"$(cut -d@ -f1 <<<"${line}")"
read fc <<<"$(cut -d@ -f2 <<<"${line}")"
read rc <<<"$(cut -d@ -f3 <<<"${line}")"
ct="$(date -d "$(cut -d@ -f4 <<<"${line}")" +'%s')"
id_check &
}
jq -r '.[] | .[] | .id + "@" + .favorite_count + "@" + .retweet_count + "@" + .created_at' 2>/dev/null <"${infile}" | while read line
do
line_parse &
done
${T} delete status -f $(sort -u "${f}" | xargs -n100 -P$(grep -c proc /proc/cpuinfo)) 2>/dev/null
/bin/rm -f "${f}"

Experienced Unix/Linux System Administrator with 20-year background in Systems Analysis, Problem Resolution and Engineering Application Support in a large distributed Unix and Windows server environment. Strong problem determination skills. Good knowledge of networking, remote diagnostic techniques, firewalls and network security. Extensive experience with engineering application and database servers, high-availability systems, high-performance computing clusters, and process automation.

{kind=link}